이번차시는 는 지도학습 중 분류(Classification)에 대해서 학습해 보았습니다.
1. 분류(Classification)란?
정의:분류는 데이터를 특정 범주로 나누는 문제이다.
이미 정해진 그룹 중에서 새로운 데이터 A가 입력될 경우,
가장 유사한 특성을 가진 집단으로 A집단을 결정
분류 vs 회기
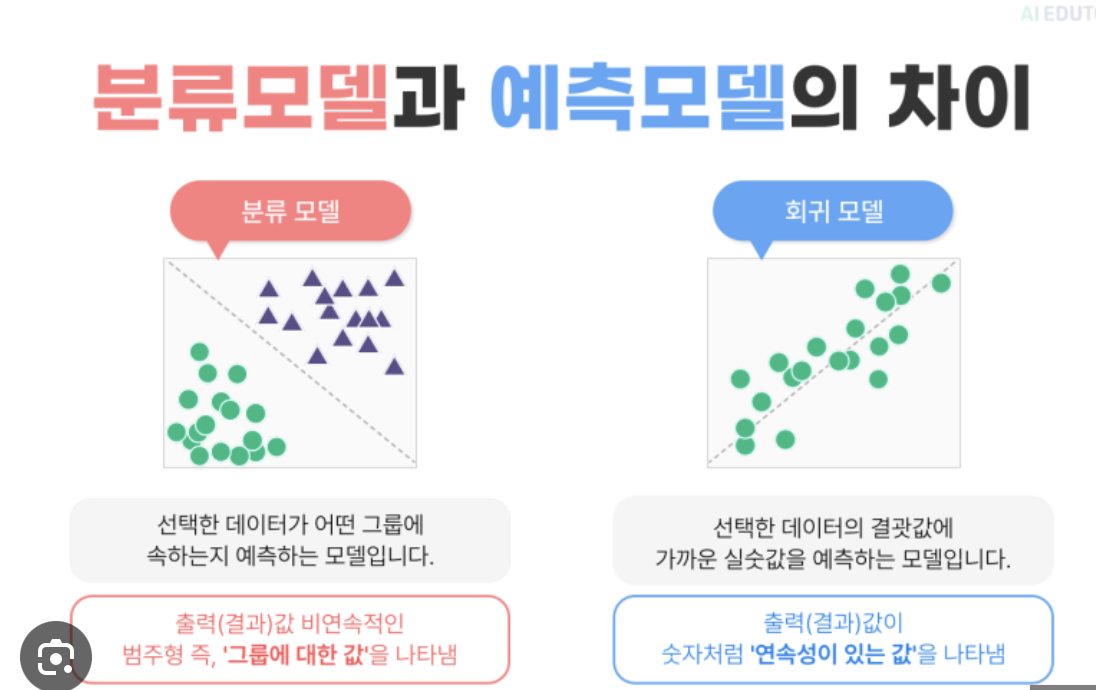
분류는 특징 같은 비연속적인 범주, 회기는 숫자에 관해 예측하는 모델이라고 볼 수 있다.
쉽게 구분하는 방법은 결과를 확인
| 회귀(Regression) | 비연속적인 범주형 값을 예측하는 것 예) 덥다, 춥다 |
| 분류(Classification) | 연속된 값을 예측하는 것 예) 32도 |
종류
- 로지스틱회귀
- 의사결정 나무
- KNN
활용예시
- 스팸메일 분류, 합격 여부
- 질병 여부
- 손글씨 숫자 분류 등
2. 로지스틱 회귀
정의: 분류에 사용하는 기법으로 선형회귀와 달리 S자 함수를 사용하여 특정 범주에 속할 확률을0에서 1사이 값으로 예측 후
그 확률이 더 높은 범주로 분류하는 이진분류모델
예측값이 기준값보다 크면 1, 작으면 0으로 분류
손실함수로 교차 엔드로피(Cross Entropy) 사용

선형회귀 vs 로지스틱 회귀
- 선형회귀 (Linear Regression)
선형회귀는 연속적인 값을 예측하는 회귀 문제를 해결하기 위한 모델
입력 변수와 출력 변수 사이의 관계를 직선(선형함수)으로 표현하여 값을 예측한다.
예를 들어,
- 집 크기를 이용한 집값 예측
- 공부 시간에 따른 시험 점수 예측
선형회귀는 다음과 같은 형태로 표현된다.
y = wx + b
즉, 입력값(x)에 대해 가중치(w)와 편향(b)을 이용해
연속적인 결과값(y)을 예측하는 모델
- 로지스틱 회귀 (Logistic Regression)
로지스틱 회귀는 분류 문제를 해결하기 위한 모델이
특히, 데이터를 특정 범주(클래스)로 나누는 데 사용된다.
선형회귀와 달리, 결과값을 그대로 사용하지 않고
시그모이드 함수(Sigmoid Function)를 적용하여 확률 값(0~1)으로 변환한다.
예를 들어,
- 이메일이 스팸인지 아닌지 분류
- 환자가 질병에 걸렸는지 여부 판단
모델의 출력은 확률로 나타나며, 보통 기준값(예: 0.5)을 기준으로 클래스를 결정한다.

표로보면 ,

장점
- 간편성 : 로지스틱 회귀 모델은 다른 ML 기법보다 수학적으로 간편
- 속도 : 로지스틱 회귀 모델에는 메모리 및 처리 성능과 같은 계산 용량이 덜 필요
- 유연성 : 두 개 이상의 유한한 결과가 있는 질문에 대한 답을 찾을 수 있음
- 가시성 : 개발자에게 내부 소프트웨어 프로세스에 대한 더 높은 가시성이 제공
시그모이드 함수
정의: 로지스틱 회귀에서 사용하는 S자 함수(확률 0~1 사이의 값)
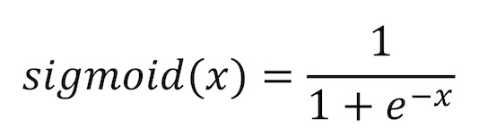
시그모이드 함수에서 기준값(보통 0.5)에 따라서 분류 결정
- 입력값이 클수록 출력값은 1의 값으로 수렴
- 입력값이 작을 수록 출력은 0의 값으로 수렴
<추가>
로지스틱 회귀 작동 순서
로지스틱 회귀는 입력 데이터를 바탕으로 확률을 계산한 뒤 이를 기준으로 분류하는 방식임. 전체 과정은 다음과 같음.
- 입력값에 가중치와 편향을 적용해서 z=wx+b 계산함
- 계산된 값을 시그모이드 함수에 넣어서 0~1 사이 확률로 변환함
- 확률을 기준값(보통 0.5)과 비교해서 최종 결과를 분류함
즉, 입력 → 선형 계산 → 확률 변환 → 기준값으로 분류 순서로 작동함.
3. 의사결정 나무(Decision Tree)
정의: 컴퓨터가 '조건에 따른 판단' 과정을 배우고,
데이터 스스로 규칙을 찾아내는 알고리즘 (입력 특징을 기준으로 데이터 분할)
예를 들어 “이 사람이 합격할까?”를 판단할 때
→ 공부시간이 많은가?
→ 시험 점수가 높은가?
처럼 조건을 나누면서 판단하는 방식임.
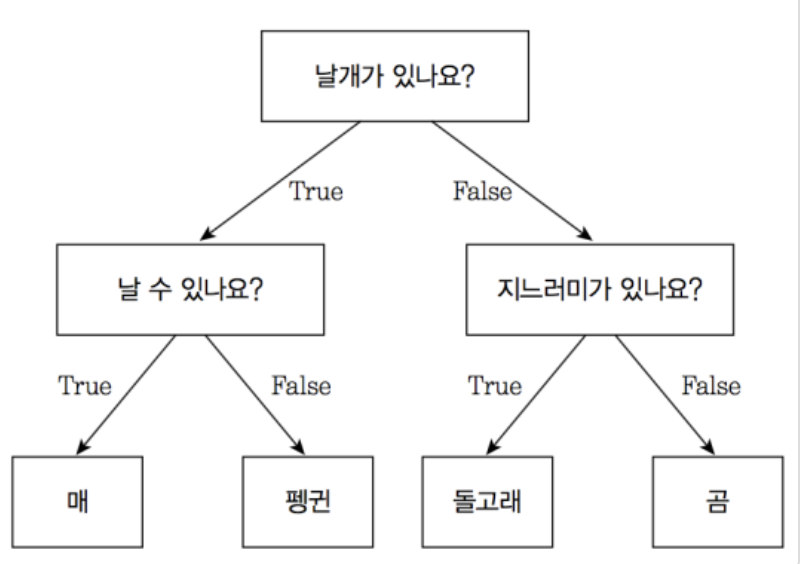
노드
- 뿌리마디(Root Node): 전체 데이터가 시작되는 최상위 마디.
- 중간마디(Internal Node): 데이터가 조건에 따라 분할되는 마디.
- 끝마디(Terminal Node): 더 이상 분할되지 않는 최종 노드(예측값), 리프노드
- 가지(Branch): 마디를 연결하는 규칙(분기).
특징
- 부모노드로부터 자식 노드의 나무 구조를 형성하는 매 단계마다 분류변수와 분류기준값의 선택이 중요함
- 분류변수와 분류 기준값: 노드(군집화)내에서는 동질성이, 노드 간에는 이질성이 가장 커지도록 선택
작동 방식
의사결정나무는 데이터를 특정 기준(조건)으로 계속 나누면서 학습
- 데이터를 가장 잘 나눌 수 있는 기준을 선택
- 해당 기준으로 데이터를 분할
- 분할된 데이터에 대해 다시 같은 과정을 반복
- 더 이상 나눌 필요가 없으면 최종 결과를 결정
즉, 데이터를 계속 분할하면서 규칙을 찾아가는 방식
의사결정 트리의 분류
- 트리의 가장 상위 조건: 전체 데이터를 크게 나누는 가장 중요한 기준(특징 중 영향력 큼 = 상위노드/ 영향력 작음 = 하위노드)
- 특정 속성이 분류 방식에 부합하게 데이터를 나누는지 측정하는 척도 : 엔트로피(Entropy), 지니계수(Gini Coefficient)
4. 분류평가지표
오차행렬 : 모델의 예측 결과와 실제 값을 비교하여 정리한 표

평가지표 5가지
- 정확도 (Accuracy) : 전체 데이터 중에서 올바르게 예측한 비율
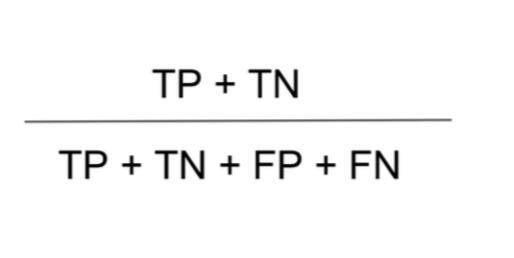
- 재현율 (Recall) : 실제 Positive 중에서 제대로 맞춘 비율
“놓치지 않고 얼마나 잘 찾아냈는가”
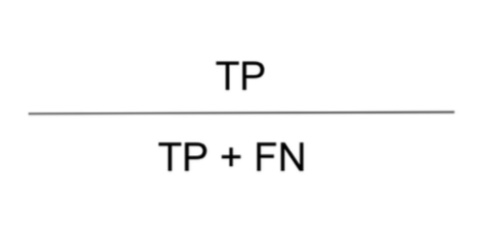
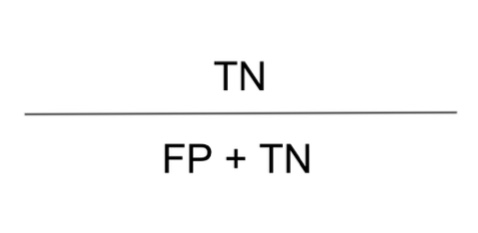
- 특이도 (Specificity) : 특이도는 실제 Negative 중에서 제대로 Negative로 예측한 비율
“내가 맞다고 한 것 중에서 얼마나 정확한가”
- F1-score : 정밀도와 재현율의 균형을 고려한 지표
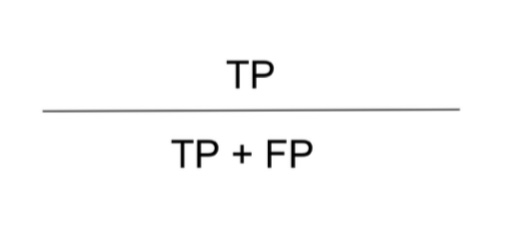
- 정밀도 (Precision) : Positive로 예측한 것 중에서 실제로 맞은 비율
“내가 맞다고 한 것 중에서 얼마나 정확한가”
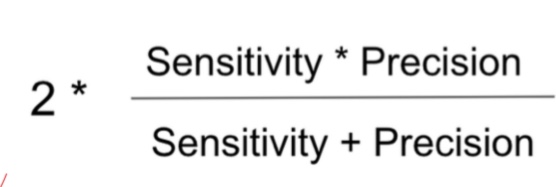
'시냅스' 카테고리의 다른 글
| [시냅스 3주차]인공신경망과 퍼셉트론 (0) | 2026.03.30 |
|---|---|
| [시냅스2주차]비지도학습과 과적합 (1) | 2026.03.21 |
| [시냅스2주차]지도학습_회귀(Regression) (0) | 2026.03.21 |
| [시냅스 1주차] 데이터 전처리와 시각화 (0) | 2026.03.16 |
| [시냅스 1주차] AI를 위한 필수 수학 & 도구 (1) | 2026.03.16 |