1. Numpy : 행렬이나 다차원 계산을 위한 파이썬 라이브러리
import numpy as np
#np.array(배열, 데이터 타입(명시하지 않으면 자동생성))
vec = np.array([1,2,3], float)
#type(객체) : 객체의 자료형
type(vec)
#vec.dtype : 배열 원소의 데이터 타입
vec.dtype
import numpy as np
# np.arange(시작, 종료, 간격)
a= np.arange(0,5,0.5)
# np.ones((depth, row, column))
b = np.ones((2,2,4))
# np.zeros((row, column))
c = np.zeros((3,4))
print(a)
print(b)
print(c)
import numpy as np
scalar = np.array(5)
print(scalar)
print(scalar.shape)
print(scalar.ndim)
#rank 0 = scalar
#rank 1 = vsctor
#rank 2 = matrix
- np.empty(): 초기화 없이 생성
- np.identity(), np.eye() : 단위 행렬
- np.diag(): 대각행렬 생성
shape: 객체의 차원 정보(어떤 구조)
- len(shape) = rank = ndim(차원의 개수)
import numpy as np
scalar = np.array(5)
print(scalar)
print(scalar.shape)
print(scalar.ndim)
#5
#()
#0import numpy as np
vec = np.array([1., 2., 3., 4., 5.])
print(vec)
print(vec.shape)
print(vec.ndim)
#[1. 2. 3. 4. 5.]
#(5,)
#1
import numpy as np
mat = np.array([
[10, 20, 30],
[60, 70, 80]
])
print(mat)
print(mat.shape)
print(mat.ndim)
#[[10 20 30]
# [60 70 80]]
#(2, 3)
#2
import numpy as np
b = np.ones((2,2,4))
print(b)
print(b.shape)
print(b.ndim)
#[[[1. 1. 1. 1.]
# [1. 1. 1. 1.]]
#
# [[1. 1. 1. 1.]
# [1. 1. 1. 1.]]]
#(2, 2, 4)
#3
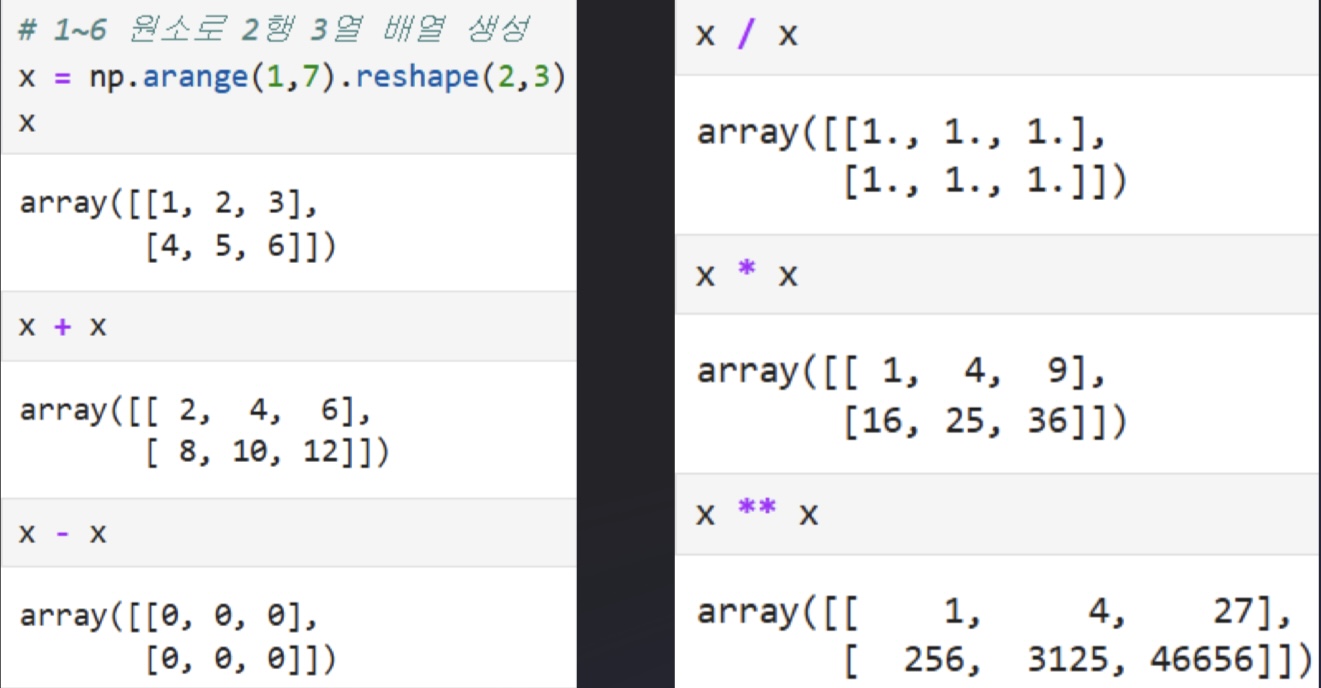
특징
연산가능
내적가능
브로드캐스팅: 하나의 행렬과 스칼라 값의 연산
import numpy as np
x_1 = np.arange(1, 7).reshape(2,3)
x_2 = np.arange(1, 7).reshape(3,2)
print(x_1)
print(x_2)
x_1.dot(x_2)
x_1 @ x_2
# 내적은 dot()함수 또는 @연산자 사용
2. Pandas : 데이터 테이블을 다루기 위한 파이썬 라이브러리
핵심

import pandas as pd
# 딕셔너리로 생성
data1 = {
'이름' : ['철수', '영희', '민수'],
'나이' : [21, 35, 26],
'성별' : ['남', '여', '남']
}
df1 = pd.DataFrame(data1)
# dataframe 생성: pd.DataFrame(딕셔너리, index=인덱스)
# 인덱스를 미지정하는 경우 0부터 시작하는 정수 인덱스가 자동생성 됨
데이터 프레임 생성
import pandas as pd
data2 = [
[84.6, 94.5, 75.4],
[51.2, 54.5, 75.3]
]
df2 = pd.DataFrame(data2, index=['중간', '기말'], columns=[1,2,3])
데이터 조회
import pandas as pd
data = {
'이름' : ['철수', '영희', '민수'],
'나이' : [21, 35, 26],
'성별' : ['남', '여', '남']
}
df = pd.DataFrame(data)
df
# 열 조회
df.head(3) # 앞부분 3개 조회
df.tail(5) # 뒷부분 5개 조회
df['이름'] # '이름' 열 내용 조회
인덱싱
df.loc[0] # 인덱스가 0인 행
df.loc[0,'나이'] # 인덱스가 0인 행의 '나이' 값
df.iloc[0] # 인덱스가 0인 행
df.iloc[0, 1] # 인덱스가 0인 행의 1번째 열 값'시냅스' 카테고리의 다른 글
| [시냅스2주차]비지도학습과 과적합 (1) | 2026.03.21 |
|---|---|
| [시냅스2주차]지도학습_분류(Classification) (0) | 2026.03.21 |
| [시냅스2주차]지도학습_회귀(Regression) (0) | 2026.03.21 |
| [시냅스 1주차] 데이터 전처리와 시각화 (0) | 2026.03.16 |
| [시냅스 1주차] AI vs ML vs DL (1) | 2026.03.16 |