이번차시는 는 비지도학습과 과적합에 대해서 학습해 보았습니다.
1. 비지도학습
: 정답(Label)이 없는 데이터에서 컴퓨터가 스스로 패턴, 구조, 숨겨진 특징을 찾아내는 머신러닝 방식
주요알고리즘
- 클러스터링(Clustering)
- 차원 축소 방식(Dimensionality Reduction)

2. 클러스터링(Clustering)
: 유사성 또는 패턴기반으로 서로 다른 객체들을 그룹 또는 클러스터로 구성하고 분류하는 비지도 머신 러닝 알고리즘
여기서 클러스터란(Cluster) ? 군집, 덩어리
군집화아 분류랑 비슷해 보이기도 하는데
분류는 소속 집단의 정보를 이미 알고 있는 상태에서, 새로운 데이터를 비슷한 집단으로 묶는 지도 학습의 한 종류
군집화란 소속 정보의 정보가 없는 상태에서 비슷한 집단으로 묶는 비지도 학습의 종류(레이블이 없음)
즉, 기존 데이터를 특성 그룹으로 나누어 특성 그룹의 성격을 파악하는데 유용
2-1. K-Means
: 유사군집 중심점(centroid)이라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법
- 거리 기반 군집화 방법
- 중심점: 데이터에 따라 클러스터에 있는 모든 점의 평균 또는 중앙값
- k: 군집의 개수
- means: 평균, 중간값
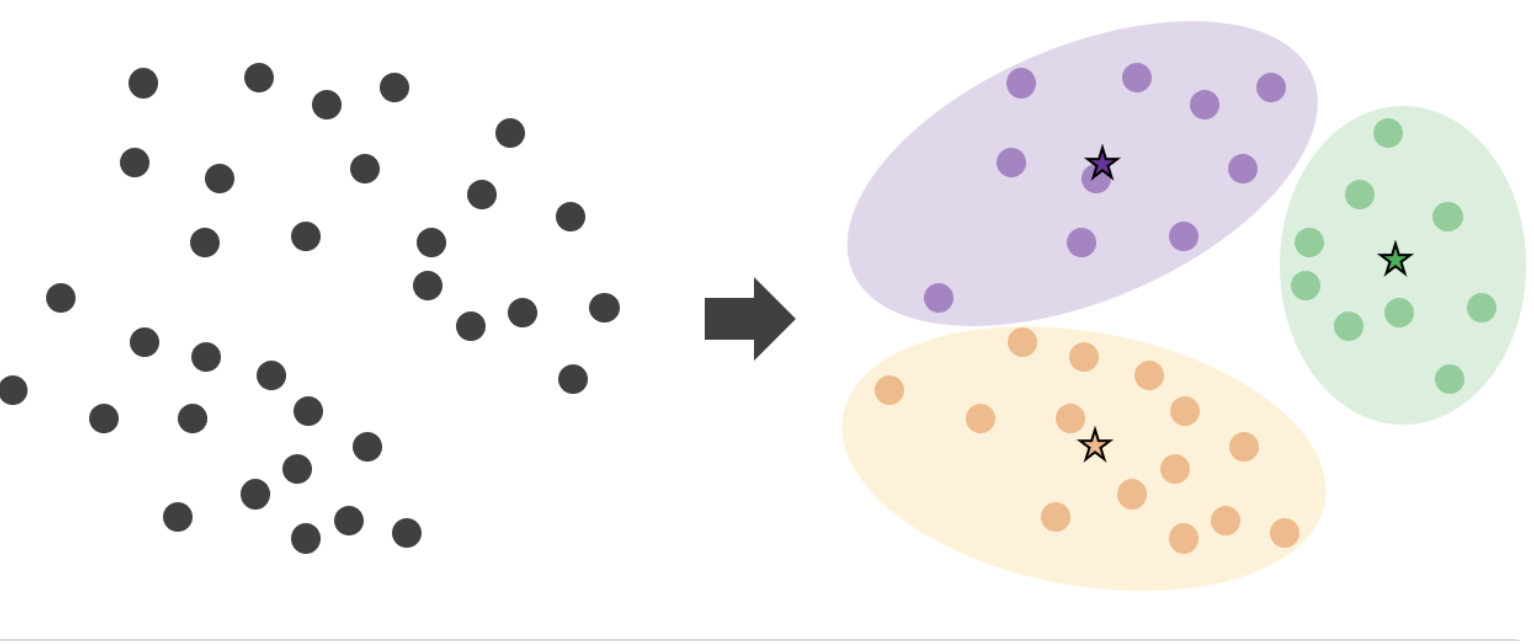
K-Means 알고리즘 과정
1. 군집의 개수(K)설정
2. 초기 중심점 설정
3. 데이터를 군집에 할당(배정)
4. 중심점 재설정(생신)
5. 데이터를 군집에 재할당(배정)
=> 중심점의 위치가 더이상 변하지 않을 때까지 4,5 반복

| 장점 | 쉽고 빠르게 연산 가능(중심점과 군집의 거리만 계산하기 때문) 데이터 사전 정보 불필요 분석 알고리즘 적용 쉬움 |
| 단점 | k(클러스터 개수)값 , 중심점(centroid)값을 임의로 정해야 함 -> centroid 값에 따라 결가가 민감하게 변함 이상치(outlier)에 민감 -> 몇개의 값이 너무 멀리 떨어져 있을 경우, 그에 맞춰 centroid를 정해서 local minimum으로 수렴 -> local minimum: 최저점이 아닌 저점 구형의 클러스터만 구현할 수 있음 -> 복잡한 형태 집단은 못 나눔 |
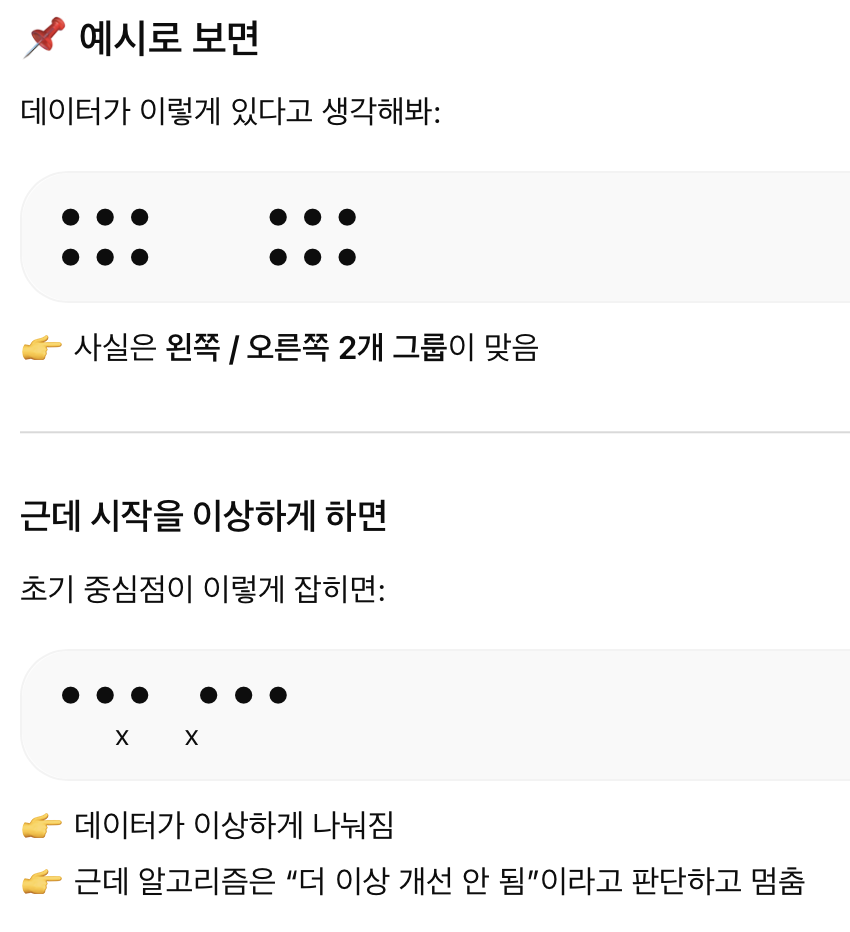
여기서 단점3은
K-means는 초기 중심점에 따라 결과가 달라지며, 전체적으로 최적의 클러스터가 아닌 부분적으로 최적인 상태(local minimum)에서 수렴할 수 있다는 뜻임
2-2. DBSCAN
: Noise를 포함한 데이터에 대해 밀도 기반으로 클러스터링 하는 알고리즘
즉, 밀도를 기반으로 클러스터를 찾는 알고리즘

점p(중심점) : 데이터 기준으로 지정
p에서부터의 거리 = eps(epsilon)
e의 반경 내의 점의 수 = minPts
직접 설정값
- minPts
- eps
DBSCAN 알고리즘 과정
1. 임의의 포인트를 선택
2. 선택한 데이터와 epsilon 거리 내에 있는 데이터 포인트 갯수가 minPts 이상이면, 해당 포인트를 중심으로 하는 Cluster를 생성
3. Cluster 안에 존재하는 다른 점 중, 다른 Cluster 중심이 되는 대이터 포인트가 존재한다면 두 Cluster는 하나의 Cluster로 간주
4. 1~4번을 모든 포인트에 대해서 반복
5. 어느 Cluster에도 포함되지 않는 데이터 포인트는 이상치로 처리

| 장점 | 기하학적으로 패턴이 있는 데이터 군집화에 유리 군집의 갯수를 정할 필요 없음 이상치는 자동으로 구분 |
| 단점 | 다양한 밀도를 가지고 있는 데이터 형태는 군집화 성능이 떨어짐 하이퍼 파라미터 값에 따른 클러스터링 결과가 크게 달라지며, 적정 파라미터 값 지정 어려움-> 하이퍼 파라미터 튜닝 필요 |
하이퍼파라미터 (Hyperparameter)
정의: 하이퍼파라미터는 모델이 학습되기 전에 사람이 직접 설정해주는 값
=> 클러스터링에서는 적절한 하이퍼파라미터 설정이 매우 중요하며 설정값에 따라 군집 결과가 크게 달라질 수 있음
3. 클러스터링 성능 평가 방법
: 클러스터링은 비지도학습이기 때문에 정답(label)이 없는 경우가 많아 일반적인 분류처럼 정확도를 바로 계산하기 어려움.
따라서 데이터의 구조나 군집의 품질을 기준으로 성능을 평가
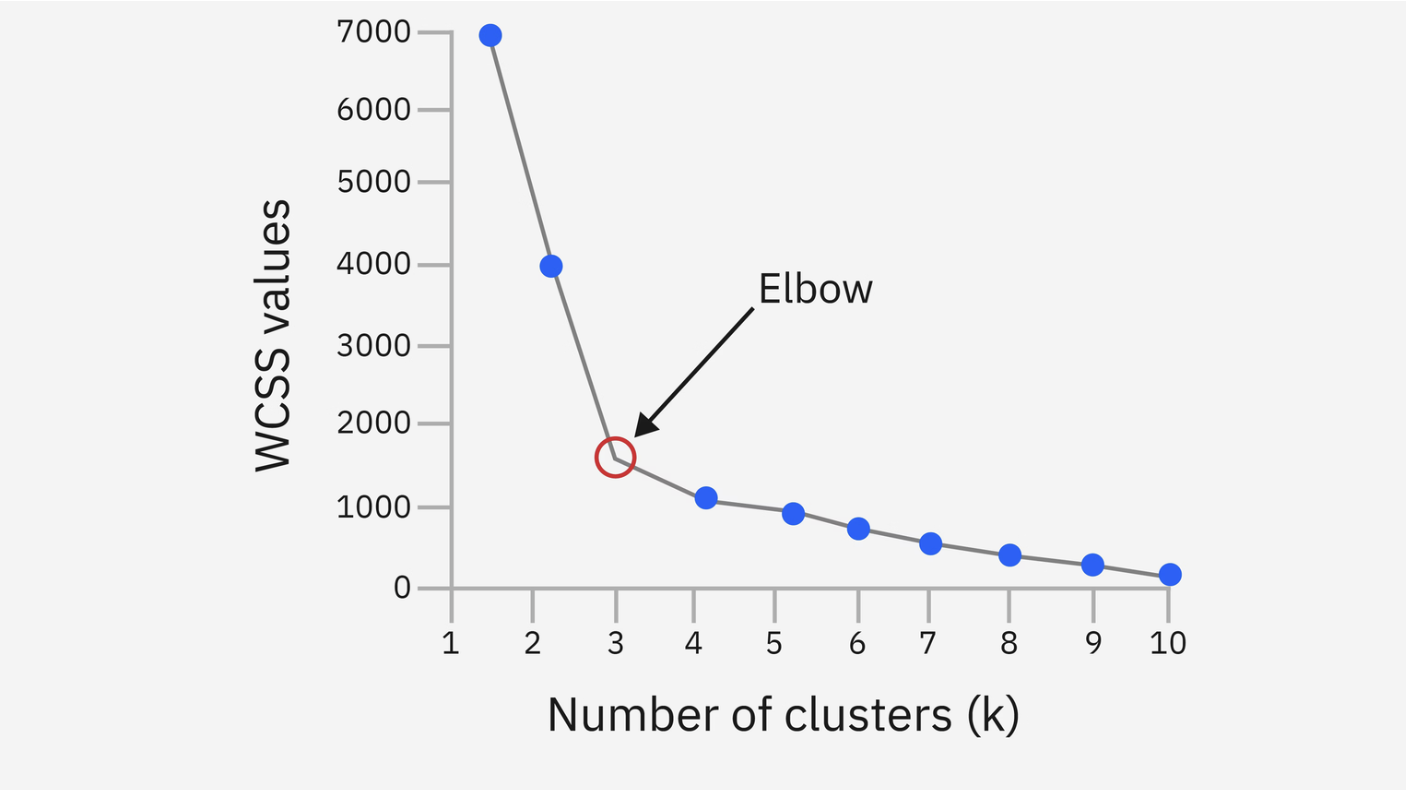
Elbow Method: 최적의 k개수 찾는 방법
cluster간의 거리의 합을 나타내는 intertia(오차)가 급격하게 떨어지는 구간을 k값의 군집 개수로 사용
* intertia: 군집 내부의 응집도를 수치화한 값 (SSE와 유사)
작동 방식
1. K 값을 여러 개로 설정함 (예: 1 ~ 10)
2. 각 K에 대해 K-means를 수행함
3. 각 경우의 오차(SSE, inertia)를 계산함
4. K에 따른 오차 값을 그래프로 그림
Silhouette score: 군집타당성 지표인 실루엣 점수 이용
작동 방식
각 데이터에 대해 다음을 계산
- a: 같은 클러스터 내 평균 거리
- b: 가장 가까운 다른 클러스터와의 평균 거리
이때 실루엣 값은 다음과 같이 계산됨
Silhouette score는 -1에서 1사이의 값이 나옴
-> -1에 가까울 수록 적절한 군집화가 되었다고 판단

4.차원 축소 방식(Dimensionality Reduction)
: 고차원 데이터의 변수를 줄이거나 결합하여 핵심 정보를 보존하면서 저차원 공간으로 변환하는 기술
PAC (Principal Component Analysis) 주성분 분석-선형 연산
: 고차원 데이터의 주요 특성을 추출하여 데이터를 낮은 차원으로 투영하는 기술
주성분: 가장 많은 정보를 담고 있는 방향
선형 연산: 비례관계 유지하는 연산(직선적으로 회전하고 압축만 하기 때문
- 데이터 분산이 큰 방향으로 선형 축소 -> 정보손실 최소화
- 겹치지 않으면서 정보를 가장 잘 설명
- 계산이 빠름(선형 연산이여서)
- 깔끔(변수간 중복 제거)

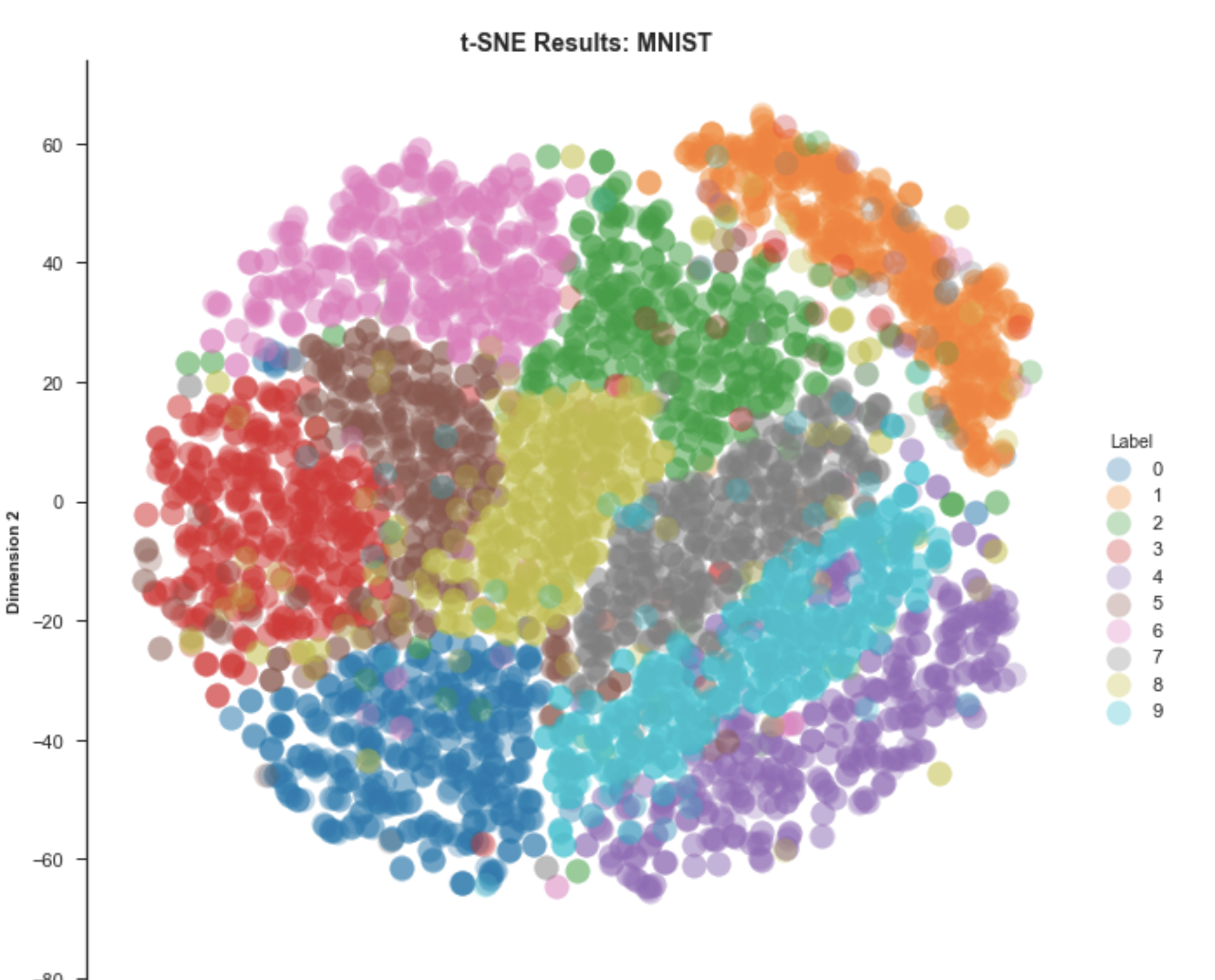
t-SNE(비선형 차원 축소 방식)
: 고차원 데이터를 저차원 데이터에 매핑하여 데이터 간의 유사성을 보존하는 기술
목적
: 고차원 데이터-> 2자원 데이터로 만듦
(고차원 공간에서 가까운 것은 저차원에서도 가깝게, 고차원애서 먼 것은 저차원에서도 멀게)
확률 분포를 이용
-> 데이터 간의 실제 거리를 유사한 확률로 바꾸는 방법
장점
- 복잡한 관계 파악에 용이
- 시각화에 유용
5. 과적합
: Training 데이터만 과하게 맞춰진 상태
-> Training 데이터에서는 성능이 높지만 새로운 데이터(Test 데이터) 에서는 성능이 떨어지는 현상 = 일반화 성능 저하
예
- k-means에서 k를 너무 크게 선택
- DBSCAN에서 eps 너무 작게 설정
- t-SNE에서 구조 과해석
-> 해결방법: 적절한 k 선택, 교차 검증 개념, 정규화, 차원축소 활용

'시냅스' 카테고리의 다른 글
| [시냅스 3주차] 딥러닝 학습의 원리 (0) | 2026.03.30 |
|---|---|
| [시냅스 3주차]인공신경망과 퍼셉트론 (0) | 2026.03.30 |
| [시냅스2주차]지도학습_분류(Classification) (0) | 2026.03.21 |
| [시냅스2주차]지도학습_회귀(Regression) (0) | 2026.03.21 |
| [시냅스 1주차] 데이터 전처리와 시각화 (0) | 2026.03.16 |