이제 3주차 마지막인데요
이번 주차 정말 양이 방대하네용.. 화이팅
1. MLP 한계
MLP 한계
1). 파라미터 폭팔
: 이미지를 그대로 펼쳐서 입력으로 사용하기 때문에
해상도가 높아질수록 파라미터 수가 기하급수적으로 증가
문제는 단순히 크다가 아닌
- 학습속도 저하
- 데이터 부족 시 쉽게 과적합
- 이미지 크기가 커질수록 계산량 폭발적으로 증가
예) 224 x 224 x 3 의 이미지 flatten 하면 총 입력 => 50,176 x 3
여기에 1,000개의 뉴련을 fully-connected로 연결하면 => 150,528 x 1,000 =150,528,000 약 1억 5천만개의 가중치
2) 공간정보손실
: flatten은 이미지의 구조를 완전히 무너뜨리는 과정이다
이미지는 원래 2D 구조여서 \(0,0), (0,1) 픽셀은 서로 이웃한 픽셀이고 근접관계가 중요한 의미 가짐
but Flatten을 하면
- 아웃한 픽셀 관계 사라지고
- 단순한 1차원 백터로 변환
=> 즉, '가까운 픽셀끼리 의미가 있는' 이미지의 중요한 특성 사라짐
이미지의 특징
- 지역성
- 패턴반복
- 위치관계
이것들이 사라짐
2. CNN
CNN 아이디어
1) 인간의 시간 인식 아이디어
: CNN은 단순히 만들어진 모델이 아니라, 인간의 시각처리방식에서 아이디어 얻음.
인간의 뇌는 이미지를 한번에 이해하지 않고, 작은 영역부터 점점 복잡학 이해
- 초기단계 : 선, 경계같은 단순 패턴 인식
- 중간단계: 단순 패턴들의 조합
- 상위단계: 물체로 인식
이것을 통해 아까 사라졌던 이미지의 특징 나타남
- 지역적 처리: 작은 영역만 보고 판단
- 패턴반복 : 특정 패턴에 반응
- 위치관계 : 복잡으로 점점 추상화
이러한 구조가 CNN 설계의 기반이 된다
수용장(Receptive field)
: 수용장은 하나의 뉴런이 실제로 볼 수 있는 영역을 의미

- 뉴런은 전체x 일부 영역만 봄
- 여러 뉴런의 수용장이 겹치면서 전체 이미지 이해
- 층이 깊어질수록 더 넓은 영역 보게됨
=> 그 결과
- 낮은 층: 픽셀 수준의 단순 패턴
- 높은 층: 더 큰 패턴과 의미있는 구조
를 학습하게 된다
CNN에서 수용장 개념
- CNN의 각 뉴런도 전체 이미지가 아니라 일부 영역만 본다
- 작은 커널(3x3)을 사용해 국소적인 특징 추출
이 구조의 장점
- 파라미터 수 크게 감소
- 이미지 공간 구조 유지
=> 수용장은 뉴런이 입력의 일부 영역만 보도록 하는 구조이며
이는 이미지에서 가까운 픽셀끼리 의미가 있다는 가정을 모델에 반영한 방식
네오 코그니트론(CNN 원형)
: CNN 의 초기 형태로 볼 수 있는 모델, 이 모델은 시각 계층 구조를 인공적으로 구현하려는 시도

핵심 구조
- S-cell : 특징을 추출하는 역할
- C-cell: 위치 변화에 강건하게 만드는 역할
현대CNN과 대응
- S-cell -> convolution
- C-cell -> Poolng
구조는 비슷하지만 다만 당시에는 학습방법 부족, 데이터 연산 자원이 부족해서 실제 성능 내기 어려움
CNN 등장
: 입력 이미지를 convolution&Poolng 반복 -> Feature map 생성 -> 완전 연결층 -> SoftMax-> 최종 확률 도출
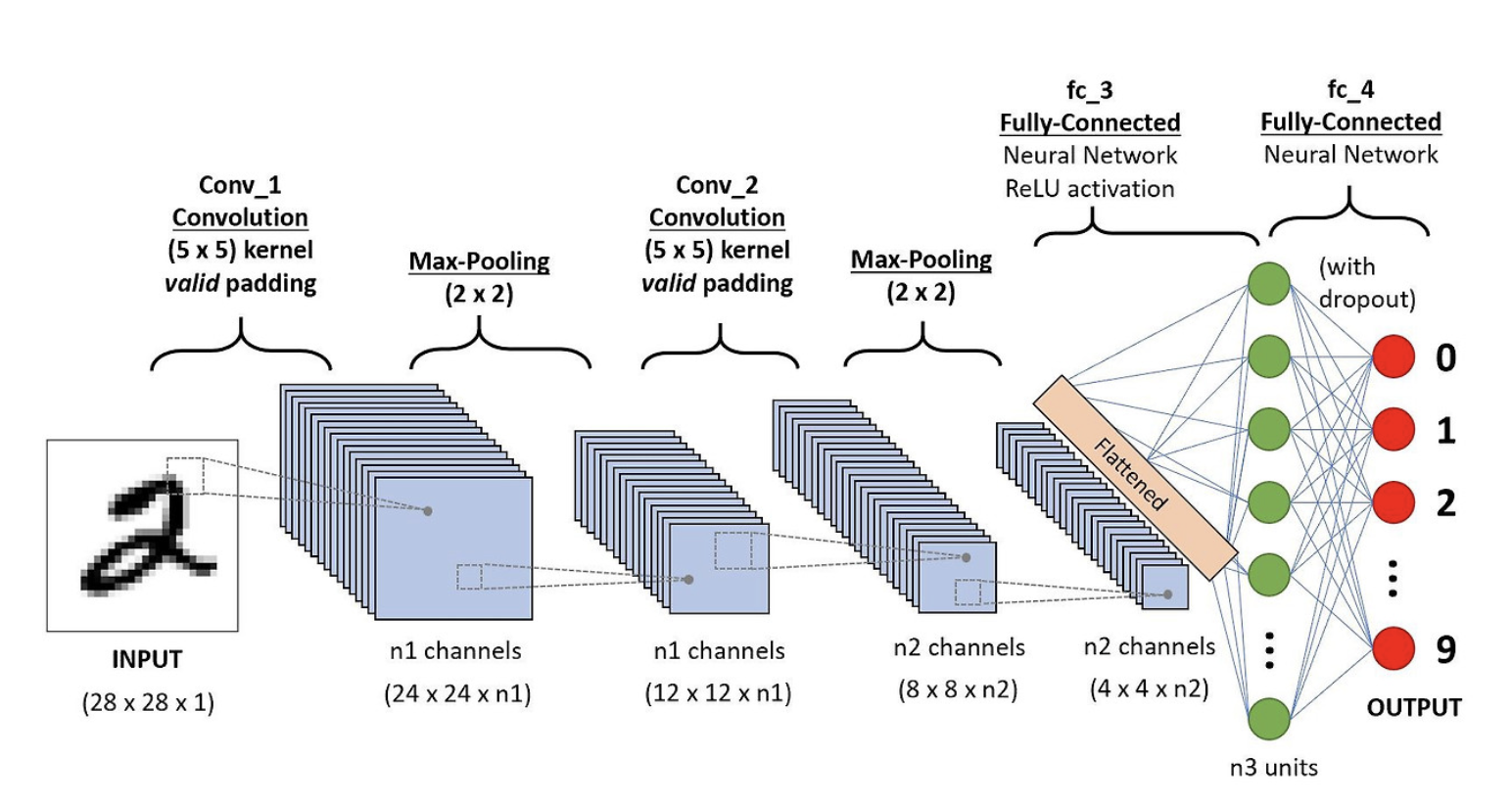
세부용어설명
Convolution
: 합성곱은 작은 필터를 이미지 위에서 슬라이딩 하며 지역적인 패턴을 찾아내는 연산
- 아래처럼 3x3 필터로 이미지 전체를 슬라이드 하면서 가중치를 곱하고 전부 더하는 mac 연산을 수행함
- 한번에 적은 수의 가중치만 학습하게 되서 MLP 파라미터 대폭 감소
nxn 채널 크기 필터가 입력 이미지 위를 stride만큼 이동
해당 영역과 곱하고 더한 뒤
bias와 activation을 적용하면
하나의 feature map이 생김


Convolution Layer의 구조를 결정하는 핵심 하이퍼파라미터
: 하이퍼파라미터란, 사람이 직접 설정하는 값
Kernel Size
: 얼마나 넓은 영역을 한 번에 볼 것인가
- 크면 → 넓은 정보, 연산량 증가
- 작으면 → 세밀한 특징, 깊이로 보완
- 요즘 CNN에서 3X3이 자주 쓰이는 이유는 표현력 대비 효율이 좋기 때문임! *(궁금하면 토글 열어보기!)*
- 5×5 필터 한 번
→ 한 번에 넓은 영역을 봄
→ 하지만 파라미터가 많고 비효율적
- 3×3 필터 두 번
→ 점점 넓은 영역을 보게 되고
→ 중간에 ReLU(비선형성)이 한 번 더 들어감
- 비슷한 크기의 영역을 보면서도 (receptive field 유사)
- 더 복잡하고 유연한 표현 가능
- 파라미터는 더 적어서 효율적
Stride
: 필터가 입력 이미지 위를 한 번에 이동하는 간격
- 크면 → 출력이 작아짐(다운샘플링 효과)
- 장점: 계산량 감소
- 단점 : 세밀한 공간 정보가 손실될 수 있음
- 작으면 → 정보 유지됨
- 보통 초기에는 stride=1로 설정하고 다운샘플링이 필요할 때만 stride=2 같은 설정을 씀
Padding
: 이미지의 가장자리를 어떻게 처리할 지 결정하는 것
- 패딩 없는 경우 (valid padding) → 출력 크기 줄어들어 경계 정보 약해질 수 있음
- 패딩으로 크기 유지하는 경우 (same padding) : 출력 크기 유지하면서 경계도 학습에 포함시키기 쉬움
- zero-padding(제로 패딩)
> 제로 패딩은 이미지 둘레에 픽셀값이 0인 추가 픽셀을 덧붙이는 것
Filter 개수
: 몇개의 특징을 추출할 것인가
- 필터수는 채널 수와 같은 의미
- 필터가 많을 수록 표현력 높아지지만 연산량 높아짐
Feature/Activation Map
:필터를 적용해서 얻어낸 결과 2D 이미지
Pooling
: Feature Map의 크기를 줄이는 연산
역할
- 추가적인 파라미터가 없어 연산량 감소
- 위치 변화에 강건함
- 중요한 정보만 남김
장점 : 불필요한 세부 정보 제거하고 핵심만 남김
단점 : 과하게 적용하면 작은 객체나 미세한 패턴이 사라지거나 위치 정보가 지나치게 무뎌짐
영역 최대값과 평균값

CNN의 Translation Equivariance & Spatial Inductive Bias
CNN의 핵심은 “같은 필터를 이미지 전체에 공유한다”
- 같은 필터를 왼쪽 위에서도 쓰고 오른쪽 아래에서도 씀
- 그로 인해 모델은 “패턴이 어디에 있든” 동일하게 인식할 수 있음
- 이 성질을 translation equivariance라고 함
=> 이미지가 이동하면 특징도 똑같이 옮겨지게 됨
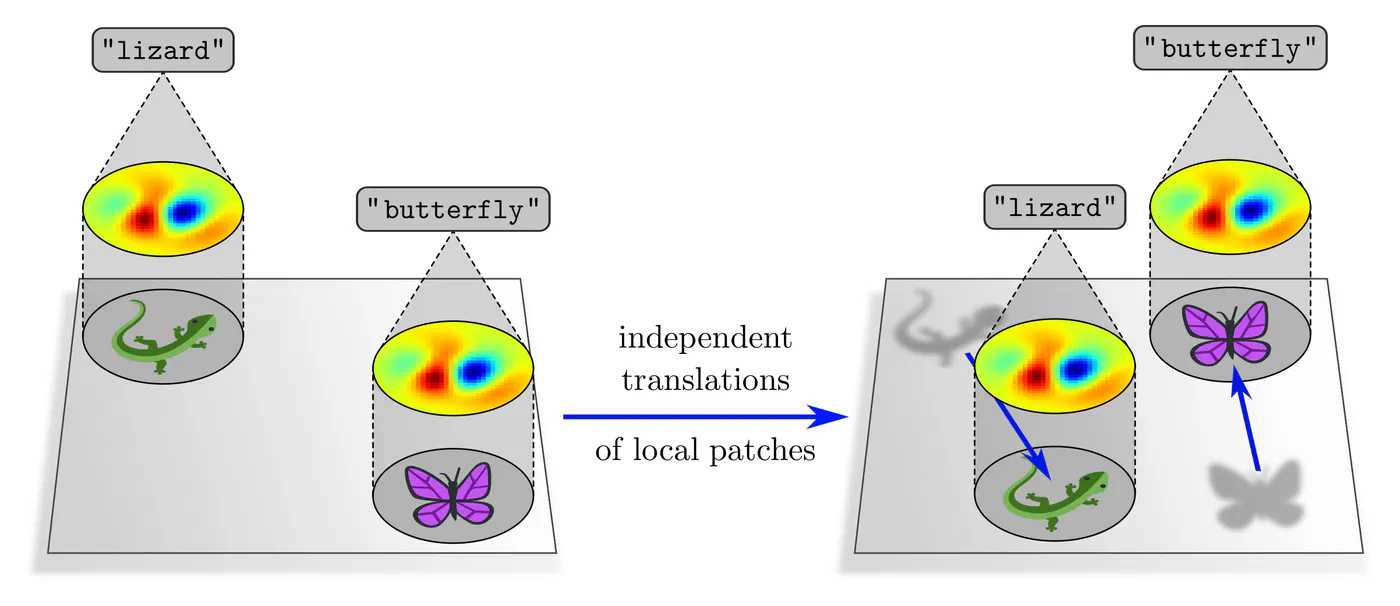
CNN의 한계
- 층이 깊어질수록 더 복잡하고 추상적인 특징을 학습할 수 있음
- 그러나, 단순히 층을 쌓는다고 성능이 좋아지지는 않음
Degradation Problem
: 층을 추가해도 일정 수준을 넘어가면 성능이 저하되는 현상
Gradient Vanishing / Exploding
: 역전파 과정에서 기울기가 너무 작아지거나 커지는 문제
- 기울기가 작아지면 → 앞쪽 레이어가 학습되지 않음
- 기울기가 커지면 → 학습이 불안정해짐
- 결과적으로 깊은 네트워크를 안정적으로 학습하기 어려워짐
연산량 증가와 비효율성
: 네트워크가 깊어지고 채널 수가 증가하면 파라미터 수와 연산량이 증가함
: 그로 인해 학습 속도가 느려지면서 모델이 무거워져 → 모바일과 실시간 환경에 적용하기 어려워짐
3. ResNet 등장
: 현대 CNN의 깊은 네트워크를 안정적으로 학습할 수 있는 구조 필요=> 그 해결책으로 등장
현대 CNN 구조의 기반
특징
- 깊은 네트워크 학습 가능
더 복잡하고 추상적인 특징을 학습할 수 있음 - Skip Connection
정보와 기울기가 입력층까지 안정적으로 전달됨
- 현대 CNN의 BackBone으로 사용됨
전이 학습에서 가장 널리 사용되는 구조임
Residual learning(잔차학습)
: 전체를 직접 학습하는 대신 입력과 출력의 차이인 잔차만 학습하도록 만든 구조
H(x) = x + F(x)
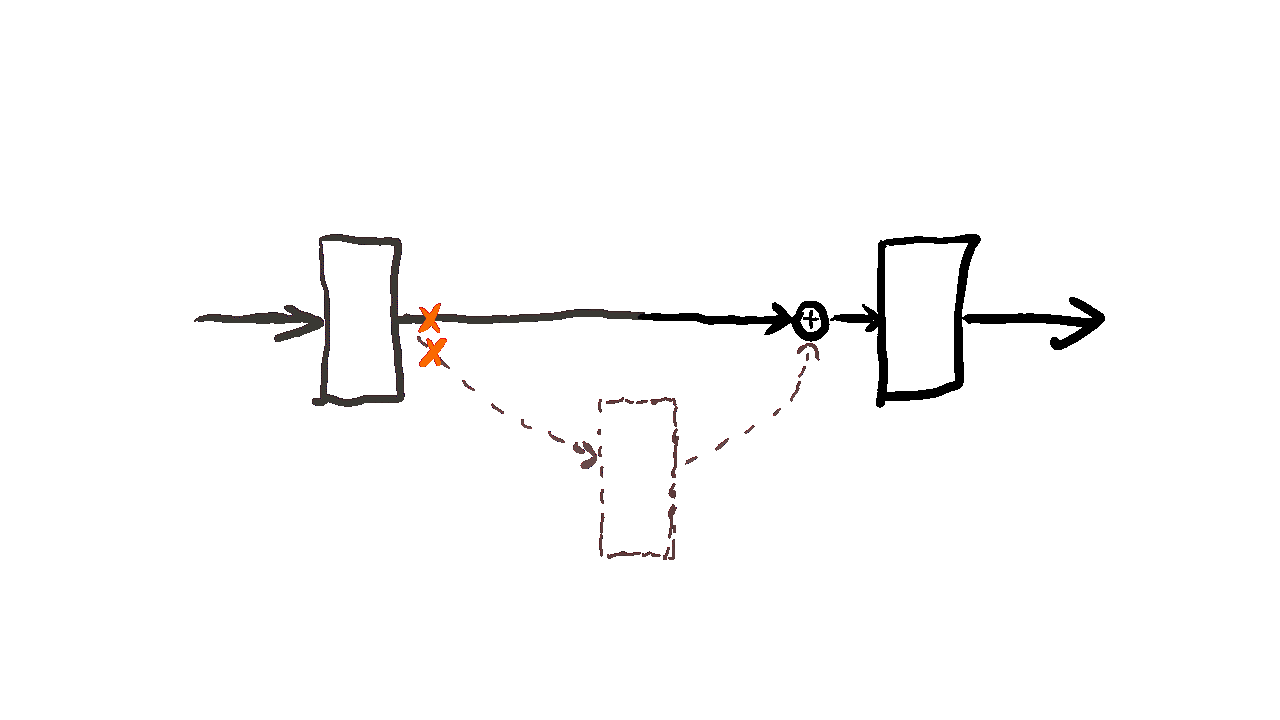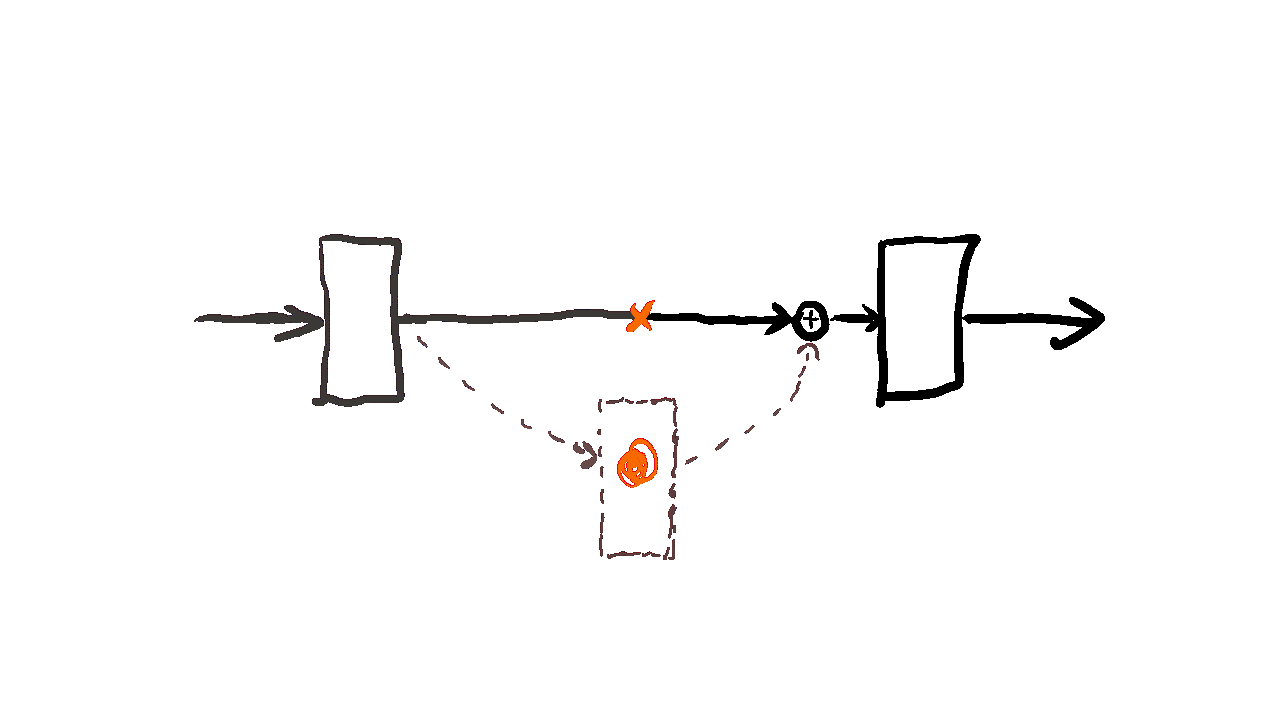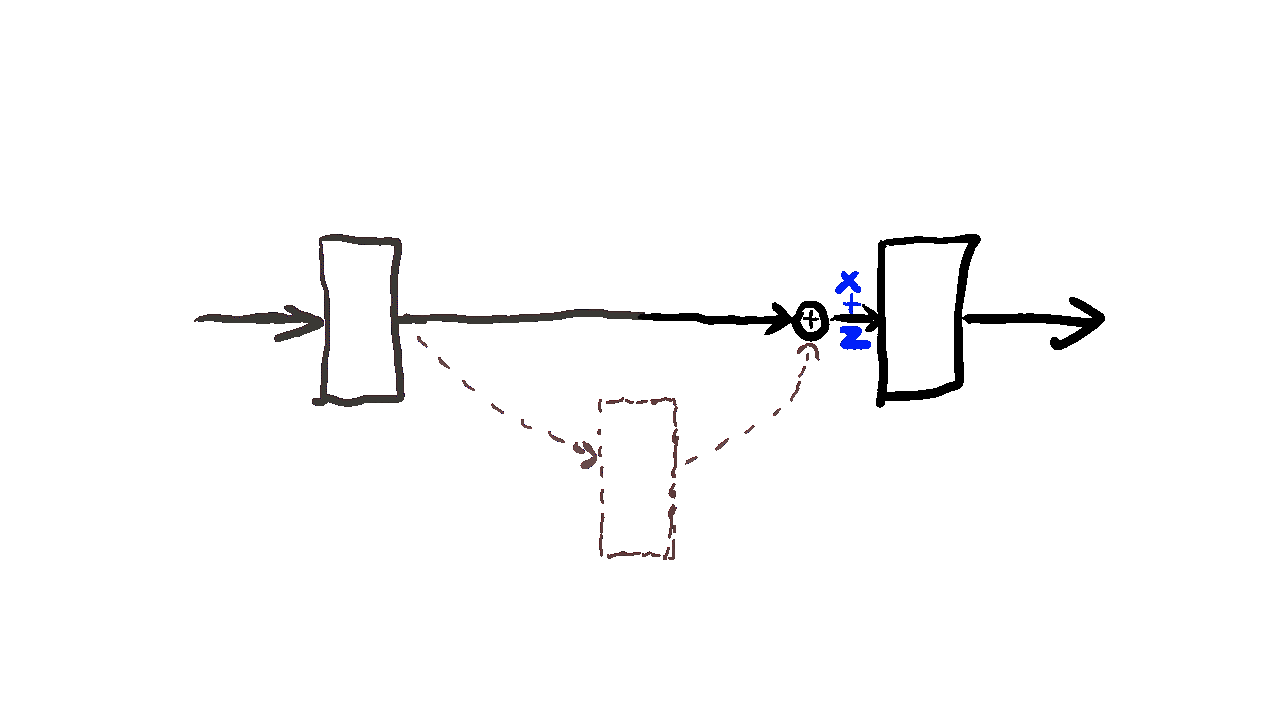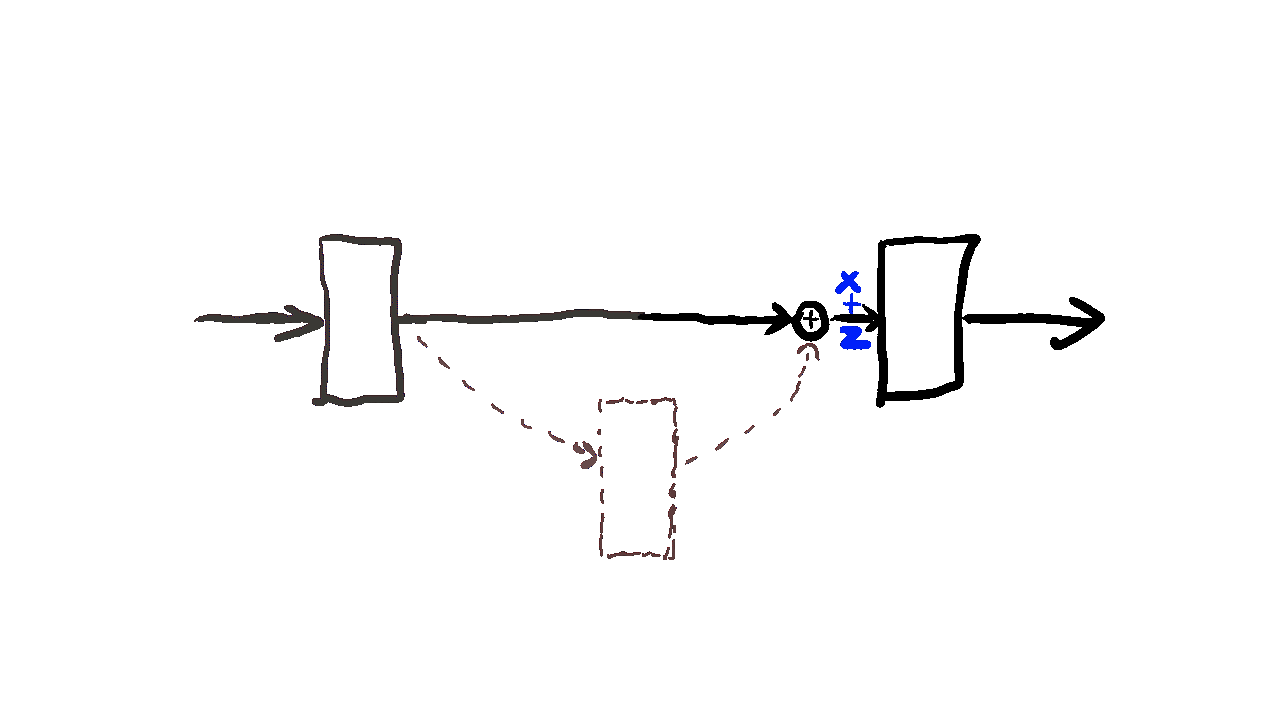
구조

3. EfficientNet 등장
: 무조건 깊은 네트워크 좋다? 그건 아님
' 모델을 더 크게 만들 때, 무엇을 키우는 것이 가장 효율적일까??'. 깊이, 너비, 해상도를 균형있게 확장하여 효율을 극대화한 모델
EfficientNet의 특징
1. ResNet 구조를 계승함
Skip Connection을 유지하여 깊은 층 학습 안정성을 확보함
2. MBConv 구조를 사용
연산량을 줄이면서도 표현력을 유지함
3. Compounding Scaling 적용
깊이, 너비, 해상도를 동시에 일정한 비율로 확장시킴
4. 높은 성능과 효율성
적은 파라미터로도 높은 정확도 달성 (SOTA 달성)
Compounding Scale
: 모델을 키울 때 하나만 늘리는 것이 아니라 세 가지 요소를 균형 있게 함께 늘리는 방법
1. 너비
채널(=필터) 수를 늘리는 것
커질수록 미세한 정보를 포착 가능
2. 깊이
레이어 수를 늘리는 것
더 복잡한 패턴 학습 가능
3. 해상도
입력 이미지 크기를 늘리는 것
상세한 정보를 유지 가능
EfficientNet의 구조
: 전체구조 Convolution -> MBConv 블록 반복 -> Feature Map 생성

- convolution 연산을 통해 기본 특징을 추출함
- MBConv 블록을 반복하면서 대부분의 연산을 진행함
MBConv 블록
: MobileNetV2의 Inverted Bottleneck 구조를 기반으로 함
1. Expansion (1x1 Conv)
→ 채널 수를 늘려서 표현력을 높임
2. Depthwise Conv (3x3 / 5x5)
- 채널별로 따로 합성곱을 수행함
- 연산량 감소
- 일반 합성곱 연산은 RGB 채널을 예로 들면 이걸 한 번에 계산하지만, Depthwise는 R 따로, G 따로, B 따로 각각 합성곱 연산을 수. 행해서 더 가벼움
3. SE Block (Squeeze & Excitement)
- 어떤 채널이 중요한지 골라내고 이 때, attention 메커니즘을 사용하여 효율성을 극대화함
4. Projection (1x1 Conv)
- 채널 수를 다시 줄임
5. Skip Connection (ResNet으로부터 계승된 구조)
- 입력값과 출력값을 더해줌
'시냅스' 카테고리의 다른 글
| [시냅스 3주차] 딥러닝 학습의 원리 (0) | 2026.03.30 |
|---|---|
| [시냅스 3주차]인공신경망과 퍼셉트론 (0) | 2026.03.30 |
| [시냅스2주차]비지도학습과 과적합 (1) | 2026.03.21 |
| [시냅스2주차]지도학습_분류(Classification) (0) | 2026.03.21 |
| [시냅스2주차]지도학습_회귀(Regression) (0) | 2026.03.21 |